
Quick-Glance Strengths
| Model | Signature Edge | Ideal Fit |
|---|---|---|
| GPT-5 | Best money-for-intelligence ratio; best math/science logic | General-purpose assists, quick prototypes, money-sensitive operations |
| Gemini 2.5 Pro | 1M-token memory plus native multimodality | Whole-codebase audits, video-heavy analytics, cross-media creativity |
| Claude 4.1 Opus | Elite coding accuracy with auditable reasoning | Mission-critical software, regulated industries, long-horizon agents |
2. Under the Hood: Feature & Cost Snapshot
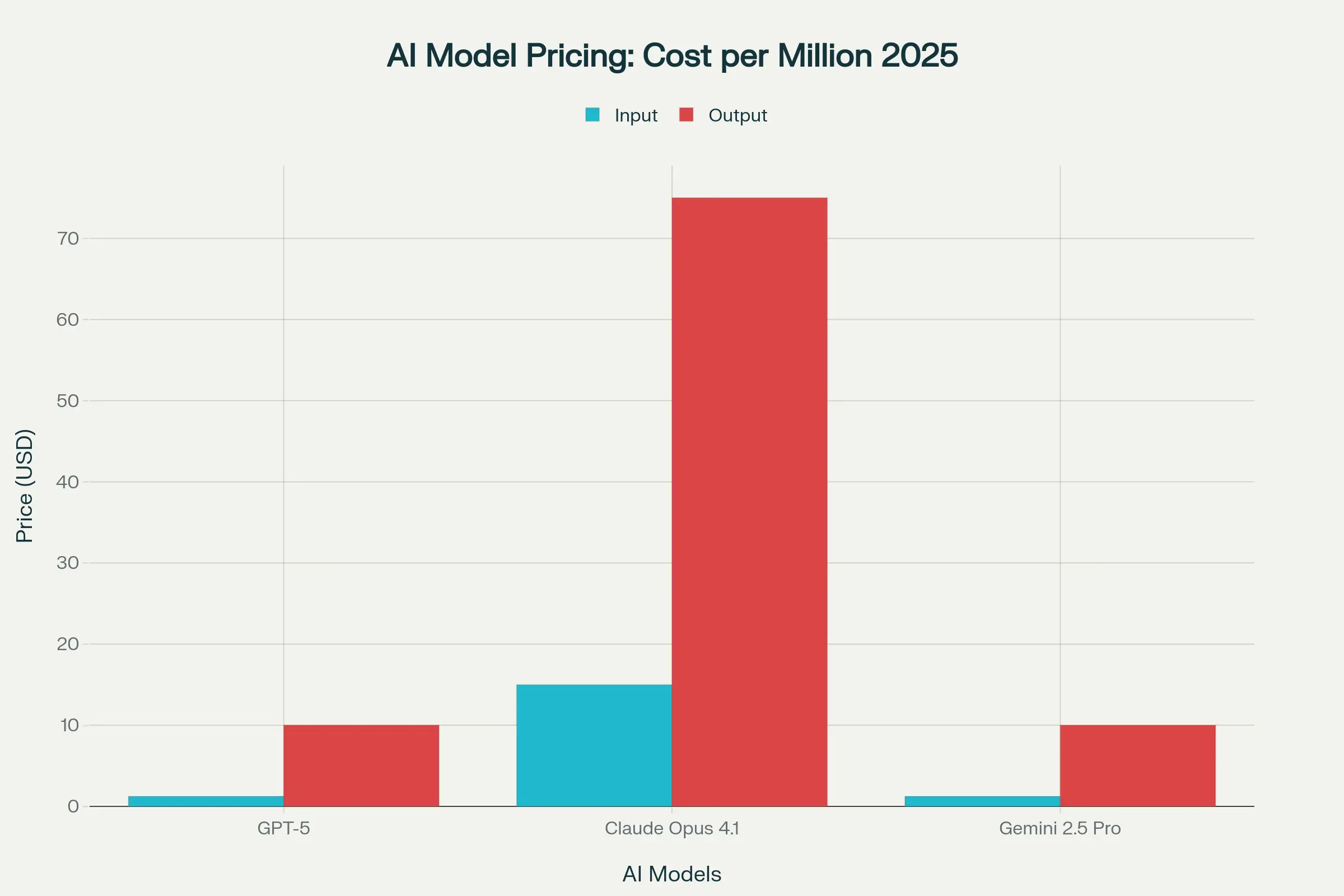
Key takeaways
- Gemini’s context window is 2.6× GPT-5 and 5× Claude, enabling single-prompt ingestion of books or repos.
- Claude’s API costs dwarf rivals—12× higher input, 7.5× higher output—but buyers pay for precision, not tokens.
- GPT-5 matches Google’s entry price yet delivers deeper math/science chops, weaponizing cost as a market lever.
3. Raw Performance Showdown
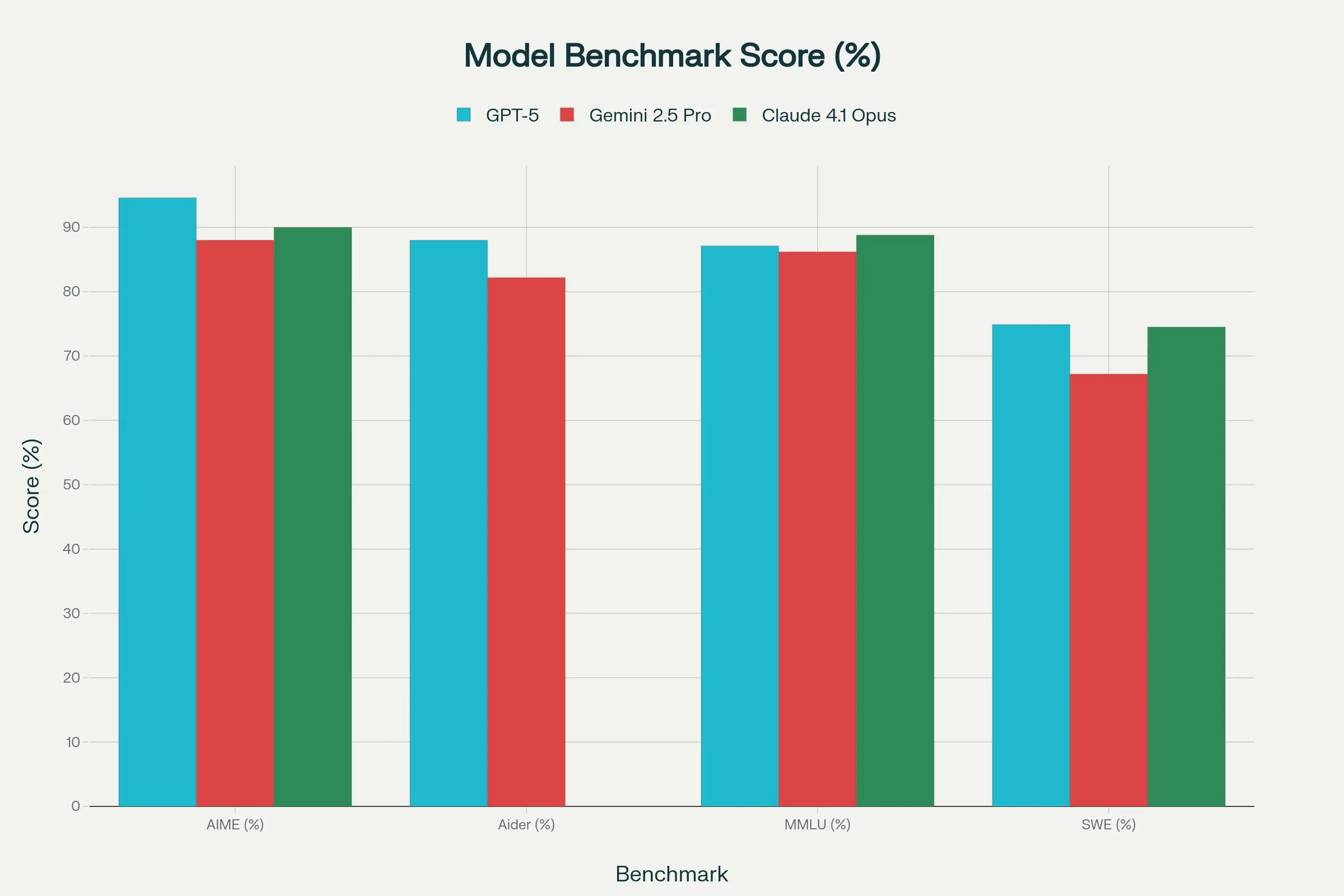
Highlights
- Reasoning parity: All three hover in the high-80s on MMLU; Claude edges ahead slightly.
- Math dominance: GPT-5’s 94.6% AIME score leads by a solid 4.6pp.
- Real-world coding: Claude and GPT-5 are statistical twins on SWE-bench; Gemini trails.
- Code-editing flair: GPT-5’s 88% on Aider Polyglot shows front-end polish, where Claude hasn’t published data.
4. Value for Money

Why this matters
- GPT-5 delivers ≈9 times the SWE value of Claude once price is factored.
- Gemini’s bargain context keeps it competitive, especially on math ROI.
- Claude remains still valuable as when a single bug costs you more than its premium bill.
5. Developer Street Talk
- GPT-5: Lightning prototyping but uneven on niche codebases unless the “thinking” mode kicks in automatically.
- Gemini 2.5 Pro: Consistently “good enough” plus enormous windows; devs praise speed and low friction.
- Claude 4.1 Opus: “Feels like pair-programming with a senior engineer” is a common refrain—if you can stomach the bill.
6. Decision Matrix
| Your Priority | Pick This Model | Why |
|---|---|---|
| Lowest TCO for everyday AI | GPT-5 | Cheapest tokens, broad skillset, strong ecosystem hooks (Azure, Microsoft 365) |
| Crunching terabytes of code, docs, or video | Gemini 2.5 Pro | 1M-token context, multimodal native, pay-as-you-grow window |
| Zero-defect enterprise software | Claude 4.1 Opus | Highest SWE-bench, transparent step-by-step mode, platform-agnostic APIs |
7. Bottom Line
There is no single “best” model—only the best fit.
- Use GPT-5 for your everyday tasks and for budget computing.
- Deploy Gemini 2.5 Pro when scale or mixed media break everyone else.
- Unleash Claude 4.1 Opus when failure simply is not an option.
Mix, match, and let each model play to its superpower. That’s the winning roster for 2025 and beyond.