
“Show me the language you code in and I’ll guess how helpful your AI buddy really is.” — a grumpy colleague after yet another Rust compile error.
Last Friday I watched our backend lead tap /** in IntelliJ and—boom—Copilot spat out an entire Java controller. Two desks over, a teammate begged the very same tool to finish a tiny Rust borrow-checker fix. Different languages, same assistant, wildly different outcomes. That scene pushed me down a rabbit hole of numbers, anecdotes, and late-night testing. Here’s what surfaced.
The Quiet Truth: AI Plays Favorites
Marketing decks shout “50 % faster shipping!”. In practice the boost swings from zip to wow depending on the file extension you’re staring at.
- In a Stanford-sized dataset (≈ 100 k devs) the average lift was 15-20 % for Python & Java—but barely a blip for niche stacks.
- Copilot’s own LeetCode marathon (50 k+ submissions) shows Java solving 3 out of 4 problems while Rust drops below two-thirds.
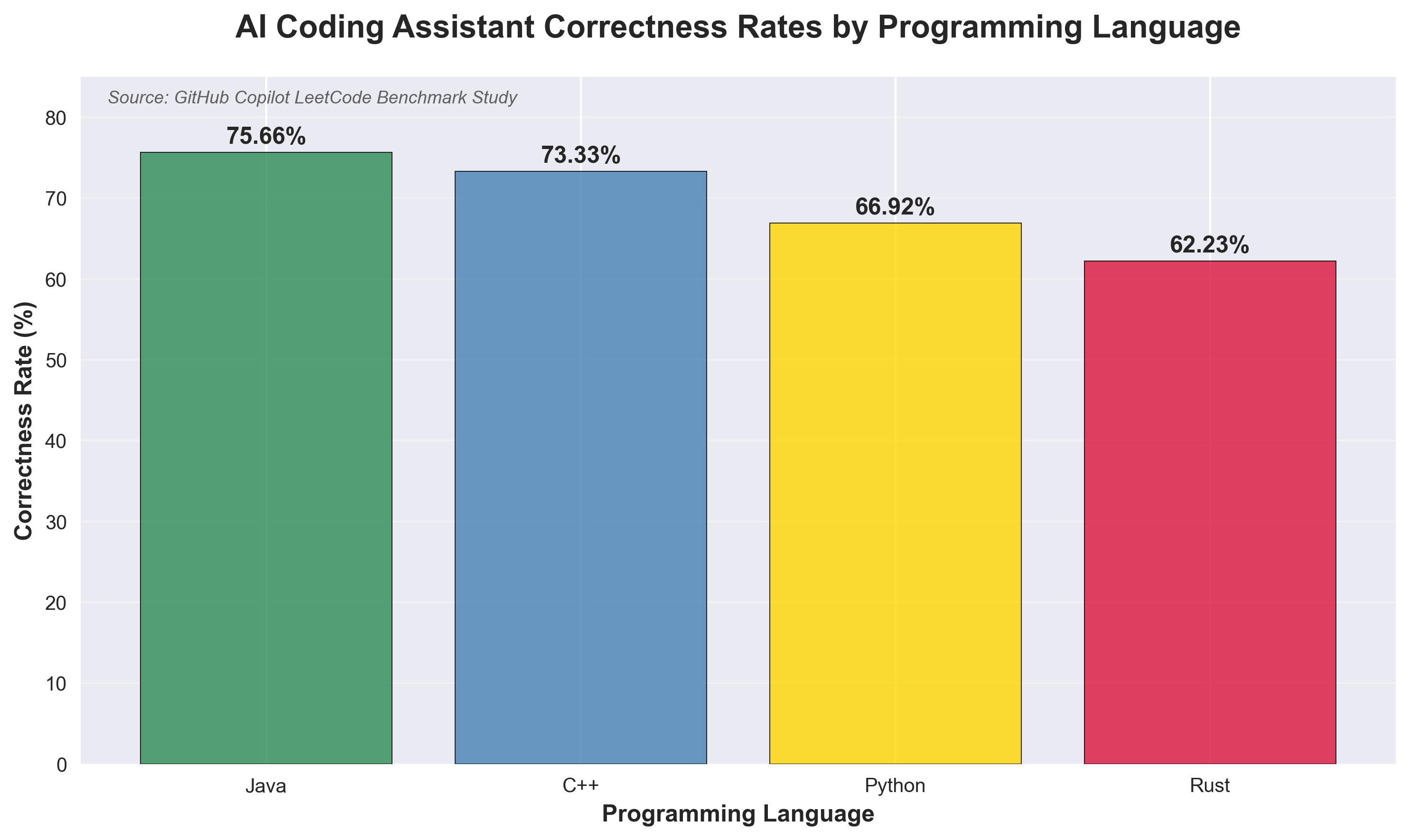
Takeaway? Language choice secretly dictates how “smart” your assistant feels.
Where the Numbers Get Loud
| Rank | Language | Correct solutions |
|---|---|---|
| 🥇 | Java | 75.7 % |
| 🥈 | C++ | 73.3 % |
| 🥉 | Python | 66.9 % |
| 4️⃣ | Rust | 62.2 % |
The gap yawns wider on “Hard” problems: Java lands every second answer, Rust barely one in three. That isn’t a rounding error—it’s hours of debugging.
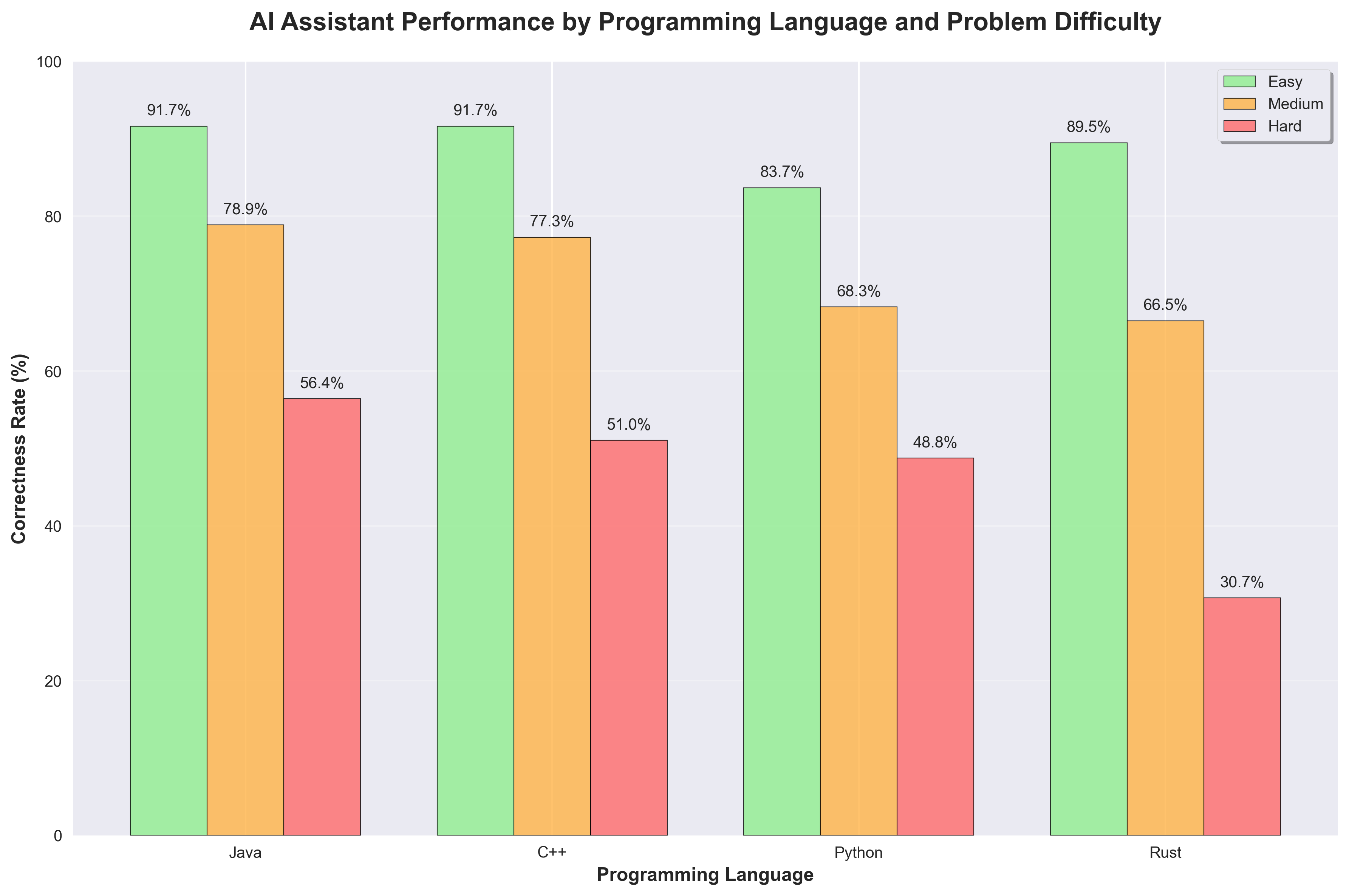
Why the Disparity Exists
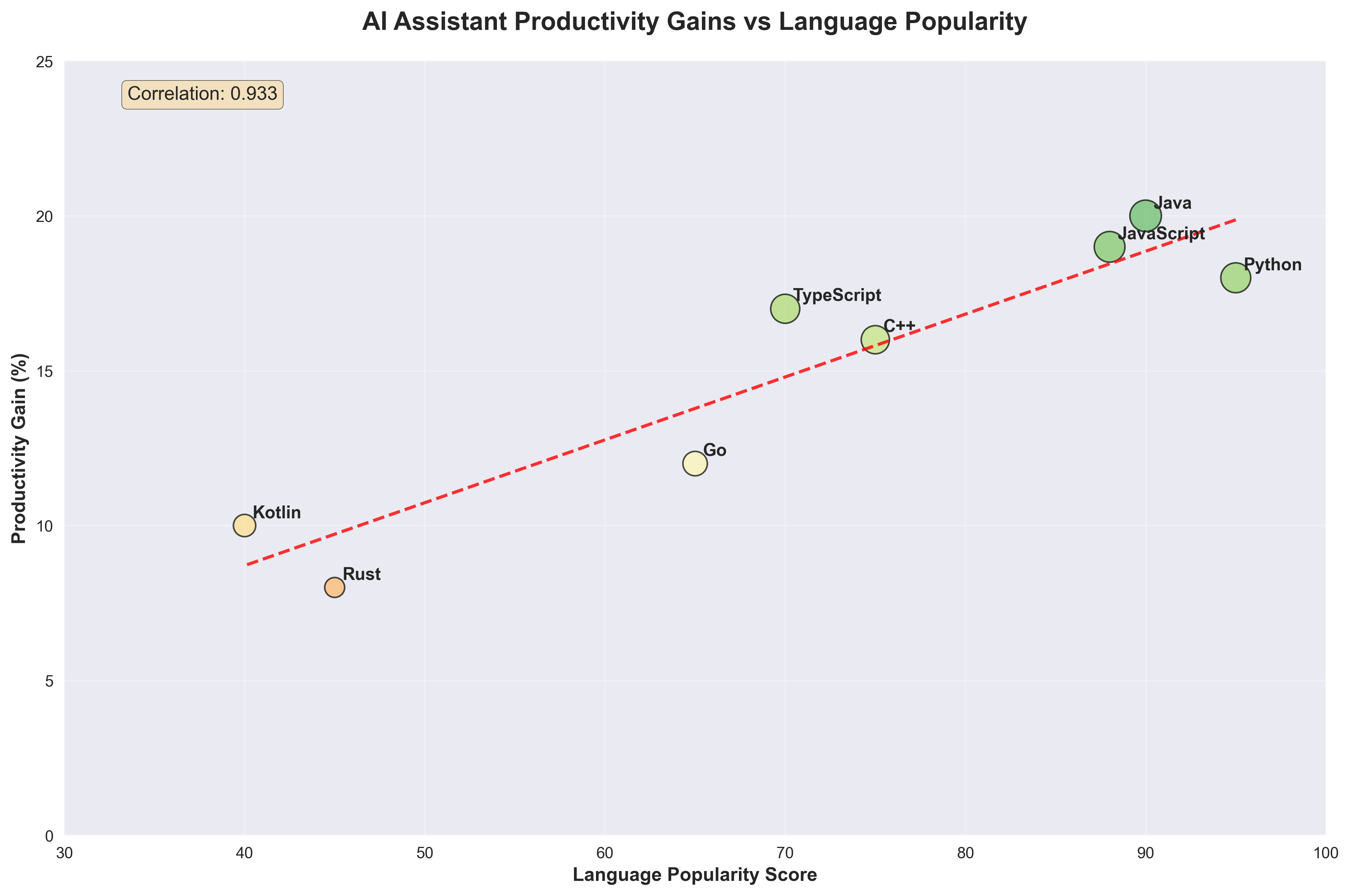
a) Training Data — Popular Kids Win
Big public codebases = rich patterns to learn. Python, JavaScript, Java? Millions of repos. Rust or COBOL? Not so much.
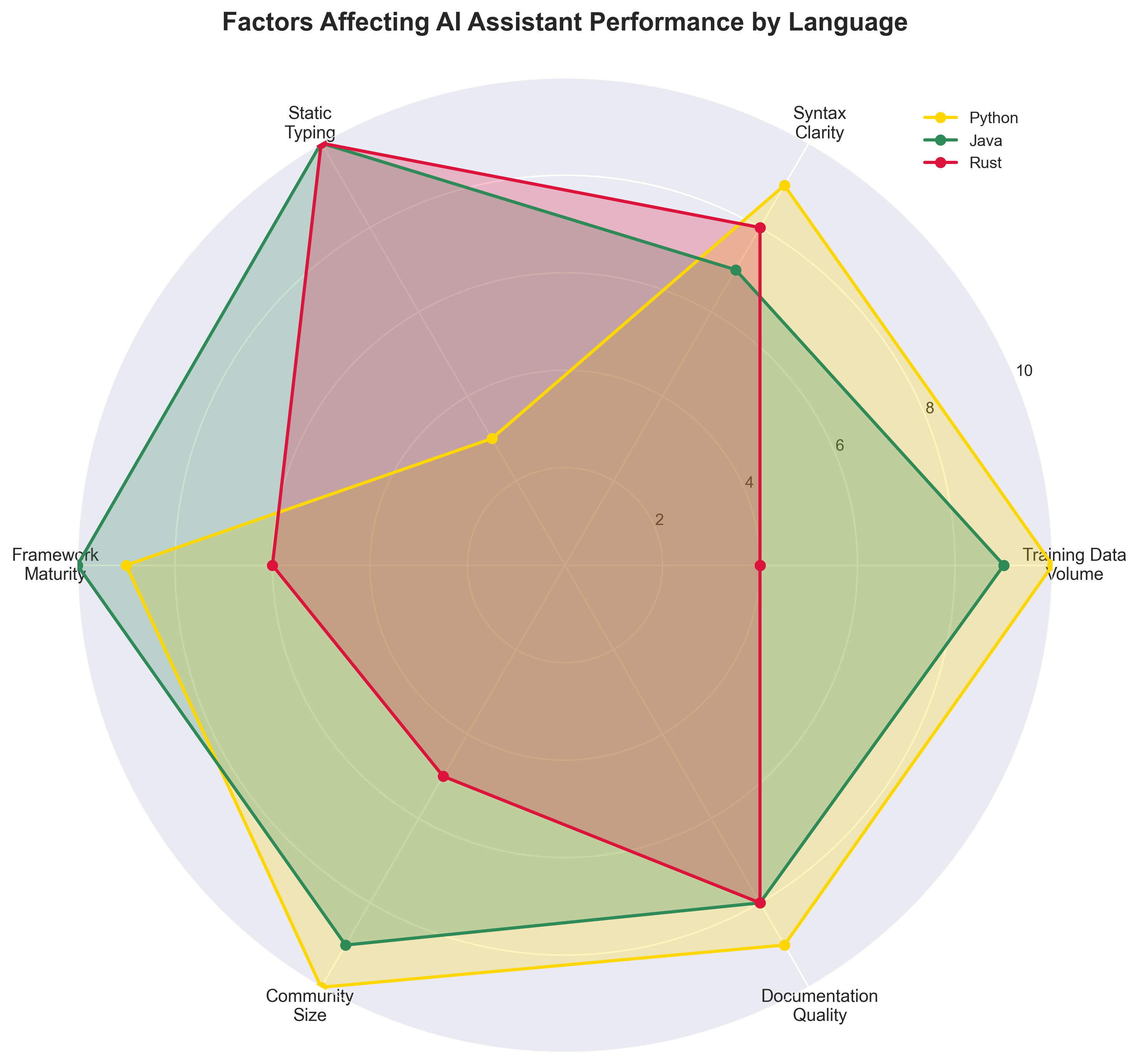
b) Language Design — Boilerplate Is a Feature (for AI)
• Static typing gives the model crystal-clear hints.
• Verbosity (looking at you, Java) forms repeatable templates.
• Novel paradigms (Rust’s ownership) trip the model up unless it has mountains of examples.
c) Framework Gravity
Spring Boot, React, Django… their opinionated patterns read like cheat-sheets for a prediction engine.
Real-World Signals
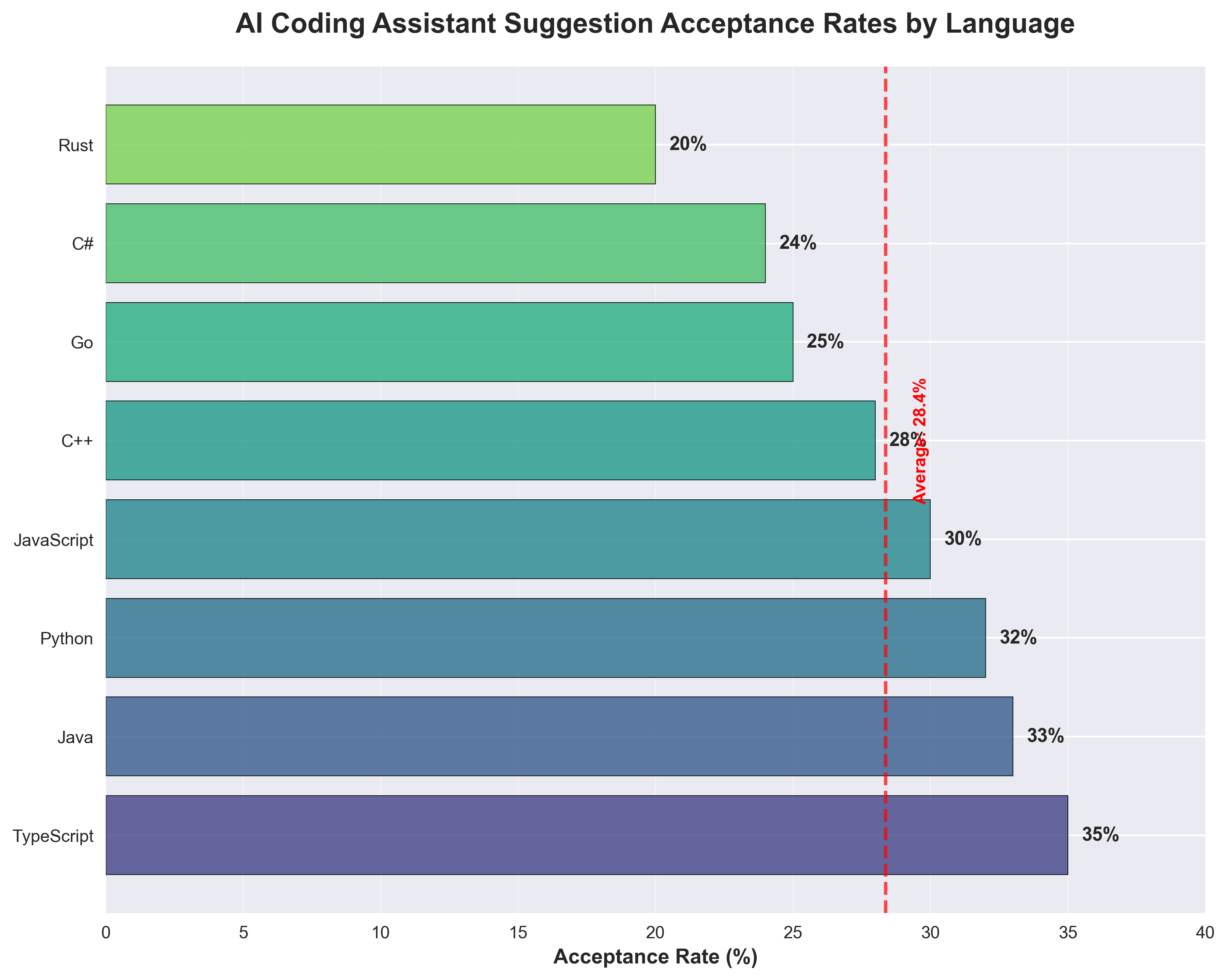
Developers vote with the Enter key. Copilot’s suggestion acceptance rates echo the benchmark pecking order—TypeScript tops 35 %, Rust hovers around 20 %.
Then there’s the perception gap: a METR study found seasoned devs felt 20 % faster yet measured 19 % slower on tough tasks. Blame cognitive bias and over-trusting auto-generated code.
Putting the Findings to Work
- Match tools to stack. Java? Embrace the bot. Niche DSL? Keep expectations low.
- Point AI at the boring bits. Boilerplate, tests, configs—it shines there.
- Use metrics, not vibes. Track review churn and bug counts, not just lines generated.
- Fine-tune if you can. Feeding private repos closes the data gap for under-served languages.
Peeking Ahead
- Specialised models: Team-trained Copilots tuned on your code.
- Language evolution: Future syntax might prioritize machine parsimony alongside human clarity.
- Agentic workflows: Today’s autocomplete grows into tomorrow’s autonomous refactor bot.
Closing Thoughts
The 20-point swing isn’t a bug—it’s the shadow of data distribution and language design. Treat AI assistants as a multiplier, but remember the coefficient changes with each .java, .py, or .rs file you open.
If you calibrate expectations—and maybe write a little less boat-anchor code—your AI pair programmer can be a force multiplier instead of a rubber duck that argues back.